웹 페이지를 통해서 커피 전문점 (할리스) 에 대한 전국 매장 정보를 크롤링 하는 실습을 해보겠습니다.
먼저 사용자가 원하는 데이터를 찾기위해 사이트에 접속합니다
https://www.hollys.co.kr/store/korea/korStore2.do?pageNo=1&sido=&gugun=&store=
할리스
HOLLYS
www.hollys.co.kr
전국 매장정보가 페이지 순으로 나타나는것을 확인
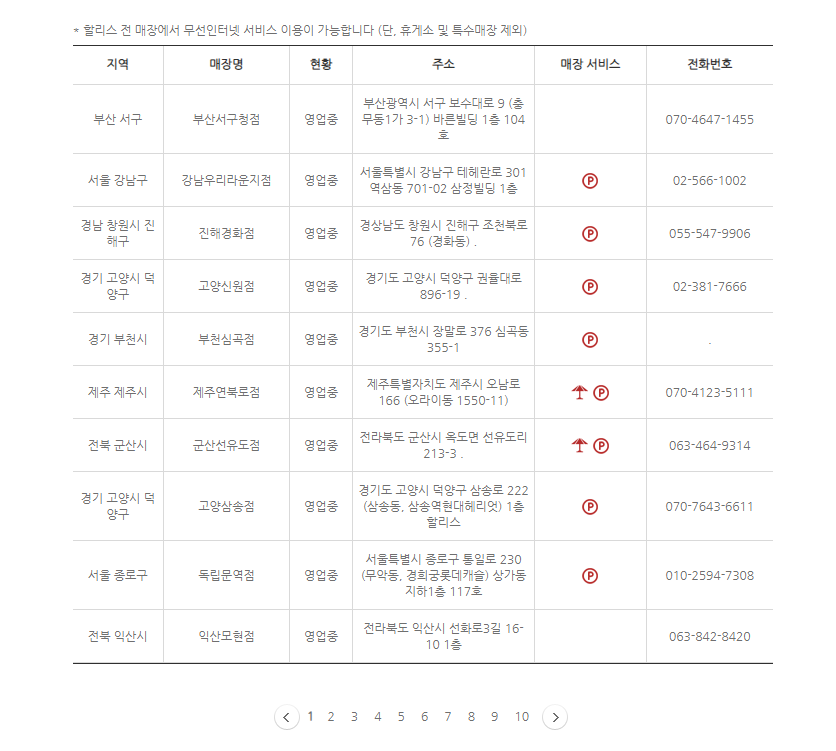
해당 URL을 보면 페이지 번호에 따라 URL이 변경됨을 확인 ( pageNo=1 , 2 , 3, ... )

CTRL + U 을 통해 전체소스를 확인하면 <tbody>안에 <tr> 안에 <td> 태그에
원하는 데이터가 규칙적으로 정렬되있음을 확인할 수 있다! ( 매우 중요 !! )

해당 URL을 가져옴으로써 Python으로 웹 크롤링 기술을 사용하여
.CSV 파일로 저장하는 작업을 진행하겠습니다.
1 ) BeautifulSoup , pandas , urllib 패키지 import 하기
from bs4 import BeautifulSoup
import urllib.request
import pandas as pd
import datetime
# 할리스 커피매장 정보를 알려주는 HTML 코드를 분석하여
# 웹 크롤링 기술을 사용하여 .csv 파일로 끌고오는 작업
2 ) URL을 가져와 해당 HTML 에 접근하여 크롤링 할 태그를 찾아 뽑아내기
#[CODE 1]
def hollys_store(result):
for page in range(1,54): # 1~54 페이지까지 검색
# pageNo만 바뀌는 형태이므로 %d 에 page 값을 넣어줌
Hollys_url = 'https://www.hollys.co.kr/store/korea/korStore.do?pageNo=%d&sido=&gugun=&store=' %page
print(Hollys_url)
html = urllib.request.urlopen(Hollys_url) # url 접근
soupHollys = BeautifulSoup(html, 'html.parser') # 해당 html 파싱
tag_tbody = soupHollys.find('tbody') # tbody 태그 찾기
for store in tag_tbody.find_all('tr'): # tbody.tr 태그를 찾아 for 문 돌리기
if len(store) <= 3: # 그 수가 3 이하면 종료
break
store_td = store.find_all('td') # tbody.tr.td 태그 구하기
store_name = store_td[1].string
store_sido = store_td[0].string
store_address = store_td[3].string
store_phone = store_td[5].string
result.append([store_name] + [store_sido] + [store_address] + [store_phone]) # 리스트에 추가
return
3 ) 데이터를 추출한 리스트를 pandas를 통해 변환후 CSV 파일로 저장
#[CODE 2]
def main():
result = []
print('Hollys store crawling >>>>>>>>>>>>>>>>>')
hollys_store(result) # [CODE 1] 호출
# pandas를 사용하여 테이블 형태의 데이터프레임 생성
hollys_tbl = pd.DataFrame(result, columns= ('store', 'sido-gu', 'address', 'phone'))
# 테이블을 CSV 파일로 저장
hollys_tbl.to_csv('C:/Users/RiGun/Python/hollys1.csv', encoding= 'cp949', mode = 'w', index = True)
del result[:]
if __name__ == '__main__':
main()
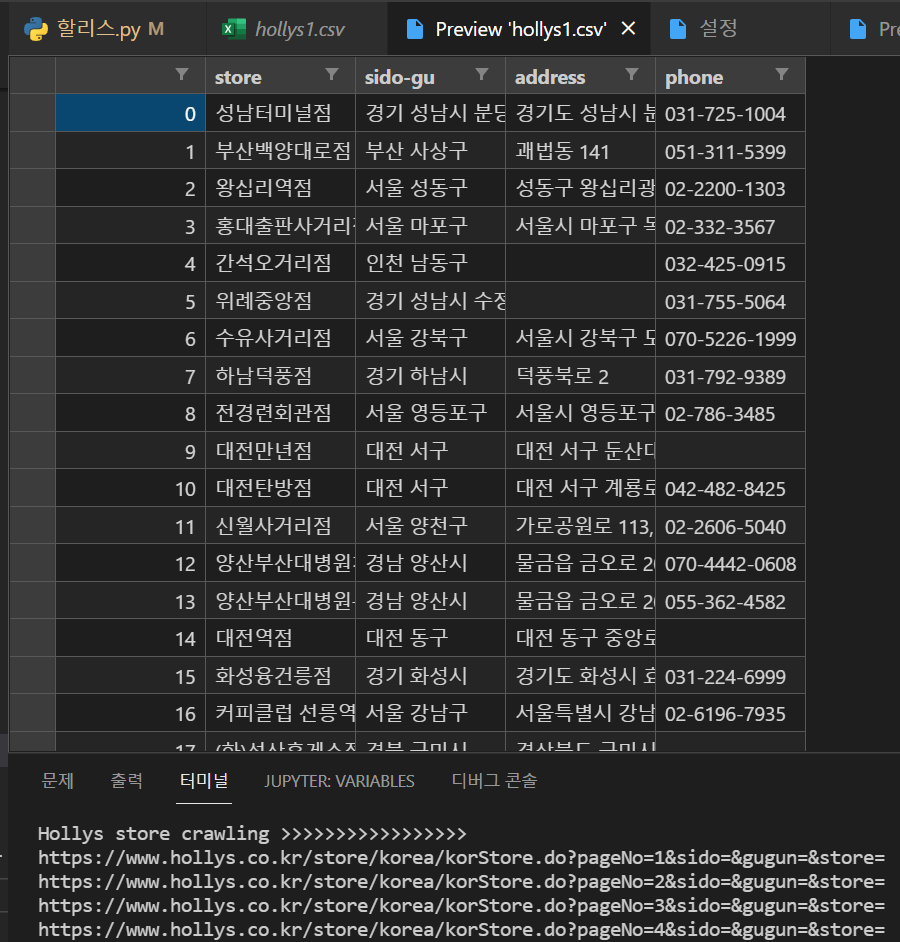
실행 결과
.CSV 파일로 저장됨을 확인 할 수 있다.
다음 시간에는 정적 페이지가 아니라 동적 페이지에서 웹 페이지를 크롤링하여 .CSV 파일로 저장하는 실습을 하겠습니다 !
'Python' 카테고리의 다른 글
| [Python] TensorFlow를 활용한 딥러닝 실습예제 (placeholder, variable) (0) | 2022.02.09 |
|---|---|
| [Python] module 'tensorflow' has no attribute 'placeholder' 에러 해결법 (0) | 2022.02.09 |
| Python 웹 페이지 크롤링 허용 여부 확인하기 (0) | 2022.02.08 |
| Jupyter Notebook 에서 !pip install wordcloud 설치 에러 해결법 (0) | 2022.02.08 |
| [Python] pip install wordcloud whl 파일 설치 에러 ( ... is not a supported wheel on this platform. ) (0) | 2022.02.08 |