[PostgreSQL] Clustering 란 ?
Clustering
일반적으로 DB 구조를 보면, DB 서버와 스토리지가 하나씩 구성되어 있다.
만약 서버가 제대로 동작하지 않으면 먹통이 된다.
실시간으로 돌아가면서 데이터 손실을 방지하기 위해서 서버를 여러개로 구성 하는 것이다.
이때, DB서버는 서로 다른 인스턴스에서 동작한다. 이 경우 서버 두 대를 하나로 묶어 운영한다.
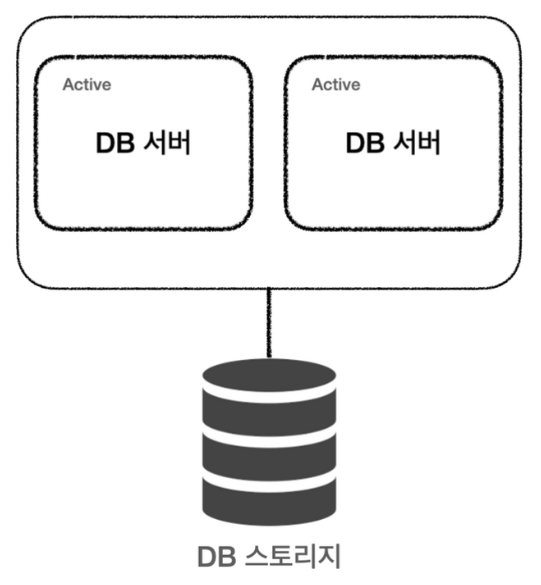
두 서버 모두 Active 상태이다.
따라서 서버 한 대가 죽더라도 하나가 동작하고 있고 그동안 복구를 하여 서비스 중단이 없도록 할 수 있다.
또한, 하나의 DB 서버에 가해지던 부하도 나눠짐으로써 CPU와 Memory 부하도 줄어들게 되어
성능 및 유지보수가 향상된다.
다만, 여러 개의 서버가 하나의 스토리지를 공유함으로써 병목현상이 발생한다.
이를 해결하기 위해서 PostgreSQL 에서는
HA ( 고가용성 ) 을 사용한다.
대부분의 DBMS는 이중화 된 두 노드가 Active-Active 또는 Active-Standby로 동작하며
문제 발생 시 Failover를 통해 서비스가 멈추는 사고를 방지
또한 DB에 전달되는 Request들을 분할 처리해 성능 향상과 안정화를 가져올 수 있다.
PostgreSQL에서는 Active-Standby 형식으로 Standby 노드는 Read만 가능하다

노드는 클라이언트와 저장소 사이를 연결해주면서, 저장소의 데이터를 읽어 올 수도 작성 할 수도 있다.
Primary 서버의 장애가 발생하여 DBMS 가 중지되면
Write-Ahead Log Shipping(WAL) 를 통해 즉시 Standby 서버가 Primary 로 운영될 수 있다.
또한 이러한 과정에서 복제 및 장애조치 및 Primary-Standby 서버를 관리하는 도구가 repmgr 이다.